NT: Esse texto é uma tradução livre do post original
Aprendizado de máquina é um tema quente seja na academia ou na indústria, com novas metodologias sendo desenvolvidas o tempo todo. A velocidade e complexidade das novas técnicas que são desenvolvidas traz dificuldades mesmo para experts - e potencialmente sobrecarregará os iniciantes.
Para desmistificar a aprendizagem de máquina e oferecer um caminho para aqueles que ainda não conhecem bem os conceitos principais, vamos dar uma olhada em 10 diferentes métodos, incluindo uma descrição, visualizações e exemplos para cada um.
Um algoritmo de aprendizado de máquina, também chamado de modelo, é uma expressão matemática que representa a informação num contexto de um problema, quase sempre um problema de negócio.
O objetivo é, partindo da informação, gerar insights. Por exemplo, se um comerciante quer antecipar as vendas para o próximo quadrimestre, ele pode usar um algoritmo que preveja as vendas com base na vendas passadas e outras informações relevantes. De forma semelhante, um fabricante de aerogeradores pode monitorar visualmente um equipamente importante, alimentando algoritmos com as imagens, treinando-os para prever possíveis falhas perigosas.
Os 10 métodos aqui descritos oferecem uma visão geral - e voce poderá aprofundar a medida que desenvolve seus conhecimentos de aprendizagem de máquina.
- Regressão
- Classificação
- Clusterização
- Redução de dimensionalidade
- Ensemble de métodos
- Redes neurais e Aprendizado profundo (Neural Networks and Deep Learning)
- Aprendizado por transferência (Transfer learning)
- Aprendizado por reforço (Reinforcement Learning)
- Processamento de linguagem natural
- Word Embeddings
NT: Algumas expressões e palavras foram mantidas em inglês por serem amplamentes referenciadas na literatura.
Uma última coisa antes de iniciarmos. Vamos distinguir entre duas categorias de gerais de aprendizagem de máquina (Machine Learning - ML): supervisionado e não supervisionado. Aplicamos técnicas de ML supervisionado quando temos partes da informação que queremos predizer ou explicar. Fazemos isso usando dados de entrada e saída previamente conhecidos para predizer a resposta para novos dados de entrada. Por exemplo, podemos usar técnicas supervisionadas para ajudar um serviço a predizer quantos usuários irão se inscrever nele no mês que vem. Já no aprendizado não supervisionado buscamos maneiras de relacionar e agrupar dados sem o uso de uma variável alvo a ser predita. Em outras palavras, os dados serão avaliados com base em suas características e com base nelas forma-se clusters (agregados) de itens que são similares entre si. Por exemplo, podemos ajudar um comerciante a agrupar produtos similares sem necessariamente nos preocupar em selecionar que características usar.
Regressão
Métodos de regresão fazem parte de uma categoria de ML chamada de supervisionada. Eles ajudam a predizer ou explicar um valor númerico em particular baseado num conjunto de dados conhecidos, por exemplo, predizer o preço de uma propriedade baseado-se nos preços de propriedades semelhantes.
O método mais simples de regressão linear é aquela em que usamos a seguinte equação, y = m * x + b, para modelar nossos dados. Treinamos um modelo de regressão linear com pares de dados (x, y) calculando a posição e a inclinação de uma reta de forma a minimizar a distância total entre todos os pontos de dados e a reta.
Em outras palavra, calculamos a inclinação (m) e o valor que interceptamos o eixo y (b) para uma linha que melhor aproxime as observações em nossos dados.
Vamos considerar um exemplo mais concreto de regressão linear. Já vez usei regressão linear para predizer o consumo de energia (em kWh) de alguns prédios, usando para isso a idade do prédio, número de armazéns, área em metros quadrados e número aparelhos ligados. Como temos mais de uma entrada, usaremos uma regressão linear multivariada. O princípio é o mesmo da regressão linear simples, com uma variável, mas nesse caso a “linha” criada está num espaço multidimensional baseado no número de variáveis.
O gráfico abaixo mostra o quão bem nosso modelo de regressão linear prediz o consumo atual de energia do prédio. Agora imagine que voce tem acesso as caracatrísticas do prédio (idade, área, etc…) mas voce não sabe o consumo de energia. Nesse caso, nós podemos usar a linha gerado pelo nosso modelo para aproximar o consumo de energia desse prédio em particular.
Note que voce pode usar regressão linear para estimar o peso de cada fator que contribui para a predição final do consumo de energia. Por exemplo, uma vez tendo a fórmula, voce pode determinar se a idade, peso ou altura é a mais importante.
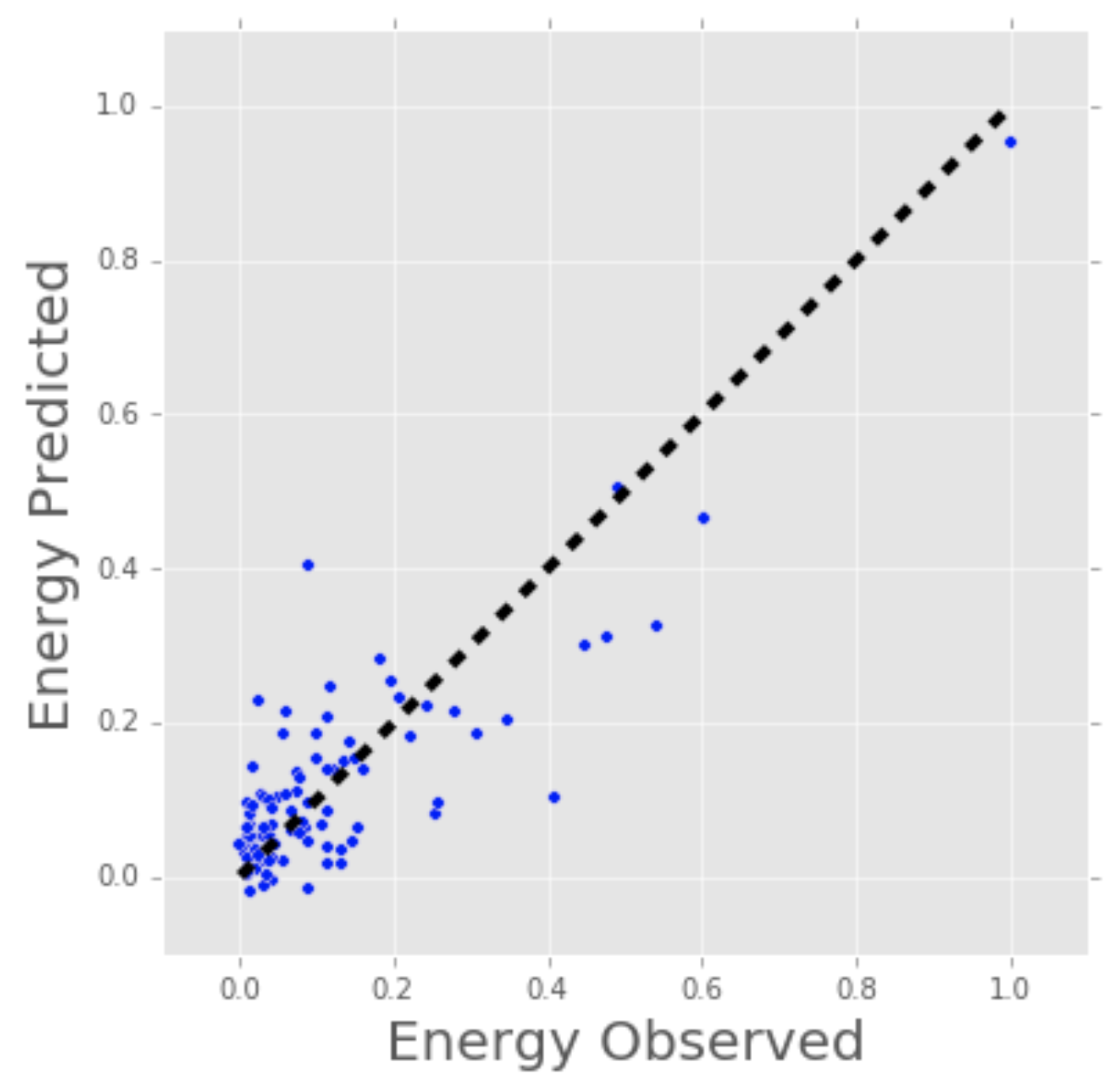 Modelo de Regressão Linear estimando o consumo de energia (kWh).
Modelo de Regressão Linear estimando o consumo de energia (kWh).
Técnicas de regressão se estende por uma gama de possibildades indo do simples (regressão linear) ao complexo (regressão linear regularizada, regressão polinomial, regressão usando árvores de decisão e florestas randômicas, redes neurais entre outras). Mas não se assuste: inicie estudando o caso mais simples e vá aperfeiçoando.
Classificação
Outra classe de ML supervisonada, métodos de classificação, predizem ou explicam a que classe um determinado valor pertence. Por exemplo, eles podem ajudar a predizer se um consumidor irá comprar um produto ou não. A saída pode ser Sim ou Não. Compra ou não Compra. Mas métodos de classificação não são limitados a duas classes. Por exemplo, um método de classificação pode ajudar a dizer se uma imagem contém um caminhão ou um carro. Nesse caso, a saída seriam 3 diferente valores possíveis: 1) a imagem contém um carro, 2) a imagem contém um caminhão ou 3) a imagem não contém nem um carro nem um caminhão.
O algoritmo mais simples de classificação é a chamada regressão logística - pode parecer que é um método de regressão, mas não é. Regressão logística estima a probabilidade da ocorrência de um evento baseado em um ou mais entradas.
Por exemplo, uma regressão logística pode a partir das notas de um aluno em duas provas estimar a probabilidade desse aluno ser admitido num determinado colégio. Por ser uma estimativa, uma probabilidade, seu valor é um número entre 0 e 1, onde 1 representa uma certeza absoluta. Para o estudante, se a probabilidade for maior que 0.5, podemos dizer que ele ou ela será admitida. Se for menos que 0.5, podemos dizer que será recusado.
O gráfico abaixo exibe os escores anteriores de estudantes juntamente com a probabilidade de serem admitidos ou não. A regressão logística nos permite traçar uma linha que representa os limites de decisão.
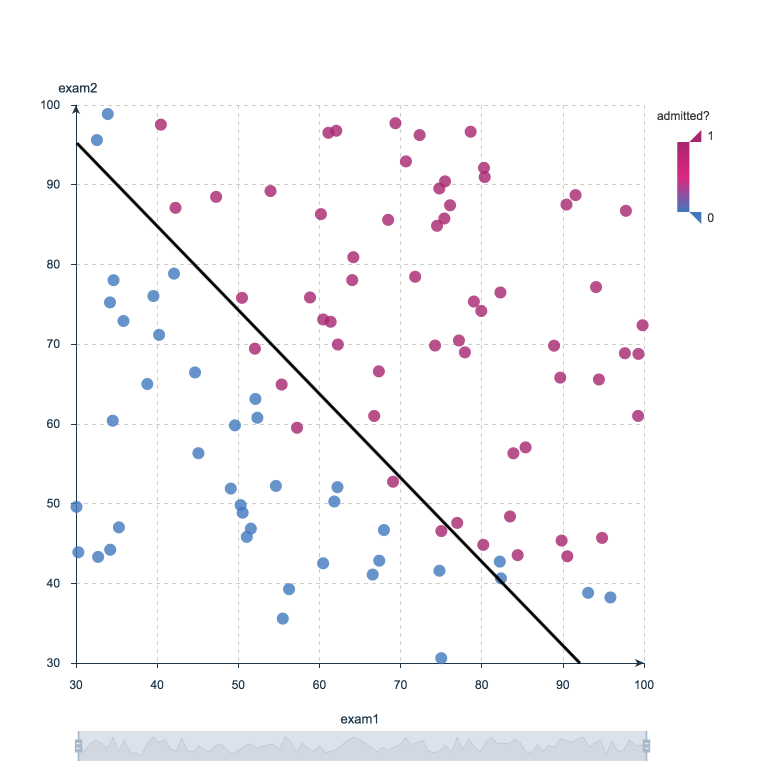 Fronteira de decisão da regressão logística: Admitido a faculdade ou não?
—
Fronteira de decisão da regressão logística: Admitido a faculdade ou não?
—
Clusterização
Com métodos de clusterização, entramos na categoria de ML não supervisionada já que o objetivo é agrupar ou clusterizar observações que tenham caracaterísticas similares. Métodos de clusterização não usam dados de saída para treino, mas deixamos o algoritmo definir a saída. Nesses métodos podemos usar visualizações para inspecionar a qualidade da solução.
O método de clusterização mais popular é o K-médias (K-means), onde “K” representa o número de clusters que o usuário quer criar. Existem várias técnicas para escolha do número de clusters, por exemplo o método elbow.
A grosso modo, o que o K-means faz com os pontos de dados, seria:
Seleciona randomicamente K centros dentro dos dados. Associa os pontos de dados ao centro mais próximo. Recalcula o centro para cada cluster. Se o centro não muda (ou muda muito pouco), o processo termina. Do contrário, repete o passo 2. (É comum setar uma quantidade máxima de interações para prevenir que novos centros fiquem sendo gerados infinitamente).
O próximo gráfico aplica K-means aos dados dos prédios. Cada coluna no plot indica a eficiência para cada prédio. As quatro medidas relacionadas a ar condicionado, equipamentos ligados (forno de microondas, refigeradores, etc), gás doméstico e aquecimento. Escolhemos K=2, para facilitar a interpretação de um dos clusters como o grupo de prédios eficientes e outro como os ineficientes. A esquerda vemos a localização dos prédios e a direita vemos duas das quatro dimensões equipamentos ligados e aquecimento.
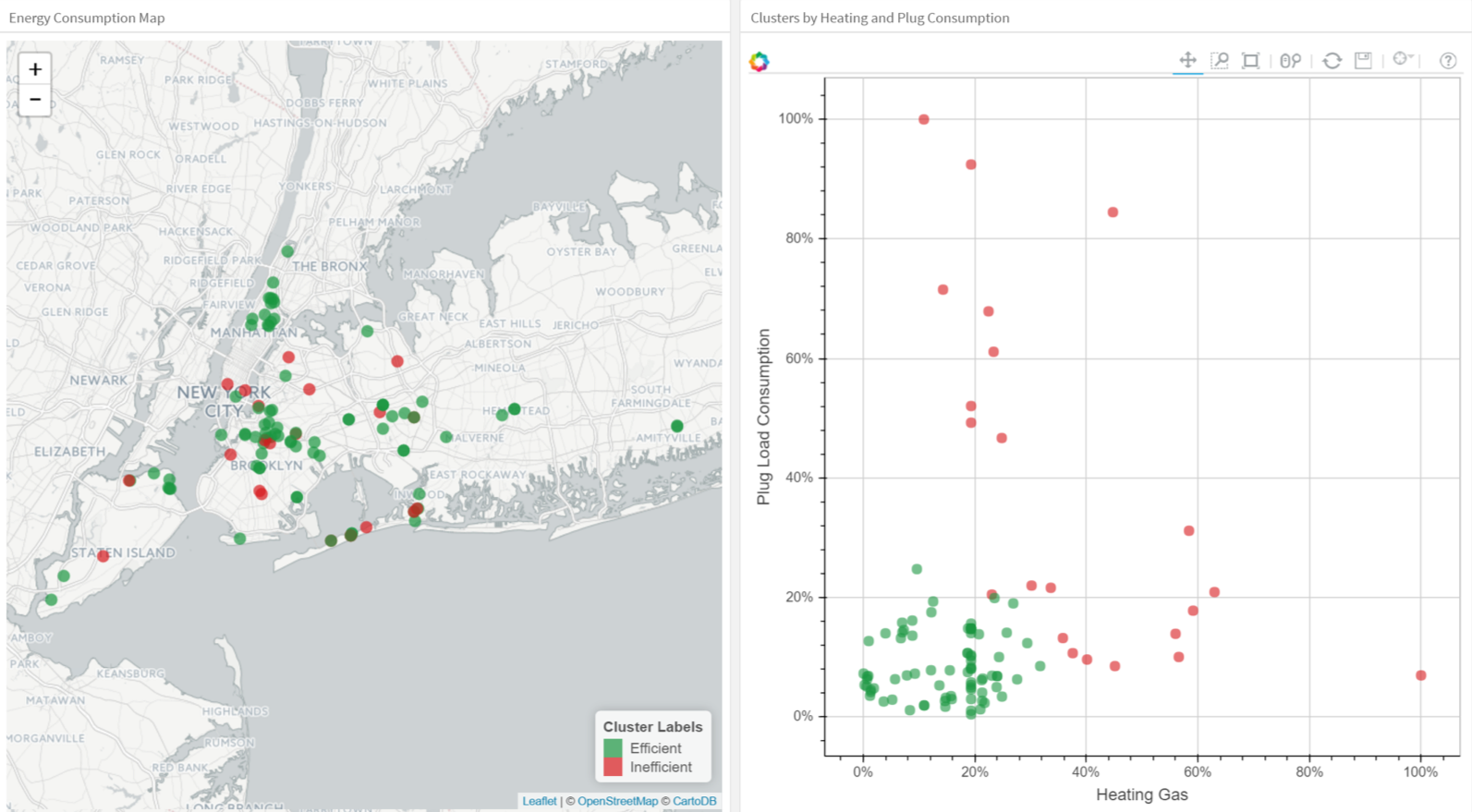 Clusterização de prédios em grupos eficiente (verde) e ineficiente (vermelho).
Clusterização de prédios em grupos eficiente (verde) e ineficiente (vermelho).
Ao explorar clusterização, voce irá encontrar algoritmos muito úteis como DBSCAN (Density-Based Spatial Clustering of Applications with Noise), Mean Shift Clustering, Agglomerative Hierarchical Clustering, Expectation–Maximization Clustering using Gaussian Mixture Models, entre outros.
Redução de dimensionalidade
Como o nome sugere, usamos redução de dimensionalidade para remover as informações de menos importância (algumas vezes redundantes) do conjunto de dados. Na prática, vemos conjunto de dados com centenas ou mesmo milhares de colunas (também chamadas de features), então reduzir o número total delas é vital. Por exemplo, imagens podem incluir milhares de pixels, nem todos interessam a nossa análise. Ou quanto testamos microchips dentro de um processo de manufatura, voce pode ter milhares de medidas e testes aplicados a cada chip, muitos dos quais nos darão informações reduntes. Nesses casos, voce precisará de algoritmos de redução de dimensionalidade para deixar seus dados gerenciáveis.
O método mais popular é o PCA (Principal Component Analysis), que reduz as dimensões dos espaço de dados encontrando novos vetores que maximizam a variação linear dos dados. PCA pode reduzir a dimensão dos dados dramaticamente e sem perda de informação quando a correlação dos dados é fortemente linear. Em tempo, voce pode medir a real extensão da perda de informação e ajustar de acordo.
Outro método popular é o t-SNE (t-Stochastic Neighbor Embedding), que realiza uma redução de dimensionalidade de forma não linear. Tipicamente se usa t-SNE para visualização de dados, mas voce pode usa-lo para tarefas de machine learning como redução do espaço de dados e clusterização, para citar algumas.
O gráfico abaixo mostra uma análise do conjunto de dados MNIST. MNIST contém milhares de imagens de dígitos de 0 a 9 que pesquisadores usam para testar seus algoritmos de classificação e clusterização. Cada linha de dado é uma versão vetorizada de uma imagem (tamanho 28x28=784) e uma legenda para cada imagem (zero, um, dois, três, etc). Note que estamos reduzindo a dimensão de 784 (pixels) para 2 (dimensões em nossa visualização). Projetando 2 dimensões nos permite visualizar a alta dimensão dos dados originais.
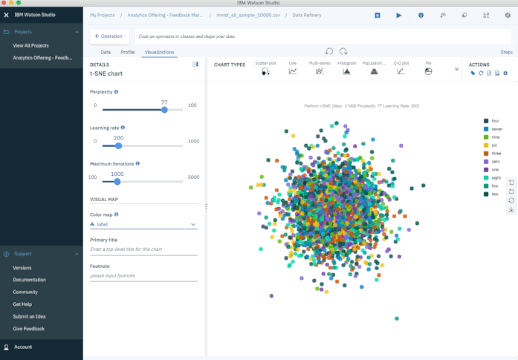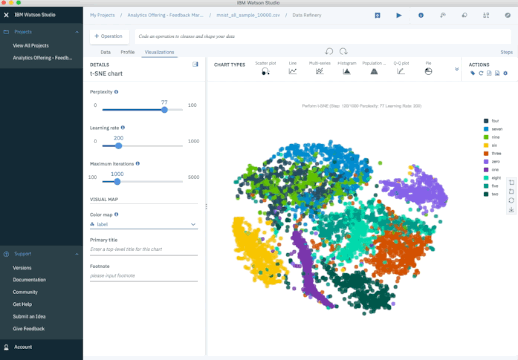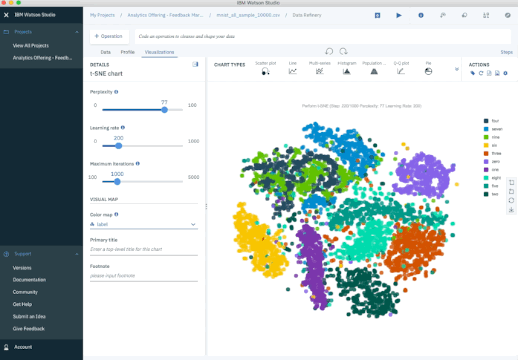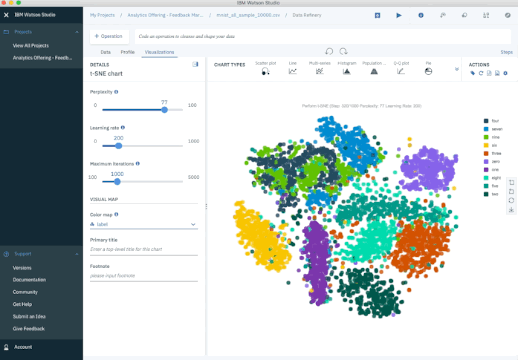
Iterações t-SNE sobre MNIST Database of Handwritten Digits.
Ensemble Methods
Imagine que você decidiu construir uma bicicleta porque não está feliz com as opções disponíveis nas lojas e online. Você pode começar encontrando as melhores partes que precisa. Depois de montar todas essas peças, a bicicleta resultante vai ofuscar todas as outras.
Os métodos de ensemble usam a mesma ideia de combinar vários modelos preditivos (ML supervisionado) para obter previsões de qualidade superior do que cada um dos modelos poderia fornecer sozinho. Por exemplo, os algoritmos de floresta aleatória (Random Forest) são um método de conjunto (Ensemble Method) que combina muitas árvores de decisão treinadas com diferentes amostras dos conjuntos de dados. Como resultado, a qualidade das previsões de uma Floresta Aleatória é superior à qualidade das previsões estimadas com uma única Árvore de Decisão (Decision Tree).
Pense nos Ensemble Methods como uma forma de reduzir a variância e o viés de um único modelo de aprendizado de máquina. Isso é importante porque qualquer modelo pode ser preciso sob certas condições, mas impreciso em outras. Com mais de um modelo, a precisão relativa pode ser revertida. Ao combinar os dois modelos, a qualidade das previsões é equilibrada.
A grande maioria dos vencedores das competições Kaggle usa algum tipo de método de ensemble.
Os algoritmos de ensemble mais populares são Random Forest, XGBoost e LightGBM.
Neural Networks and Deep Learning
Em contraste com as regressões lineares e logísticas, que são consideradas modelos lineares, o objetivo das redes neurais é capturar padrões não lineares em dados adicionando camadas de parâmetros ao modelo. Na imagem abaixo, a rede neural simples tem quatro entradas, uma única camada oculta com cinco parâmetros e uma camada de saída.
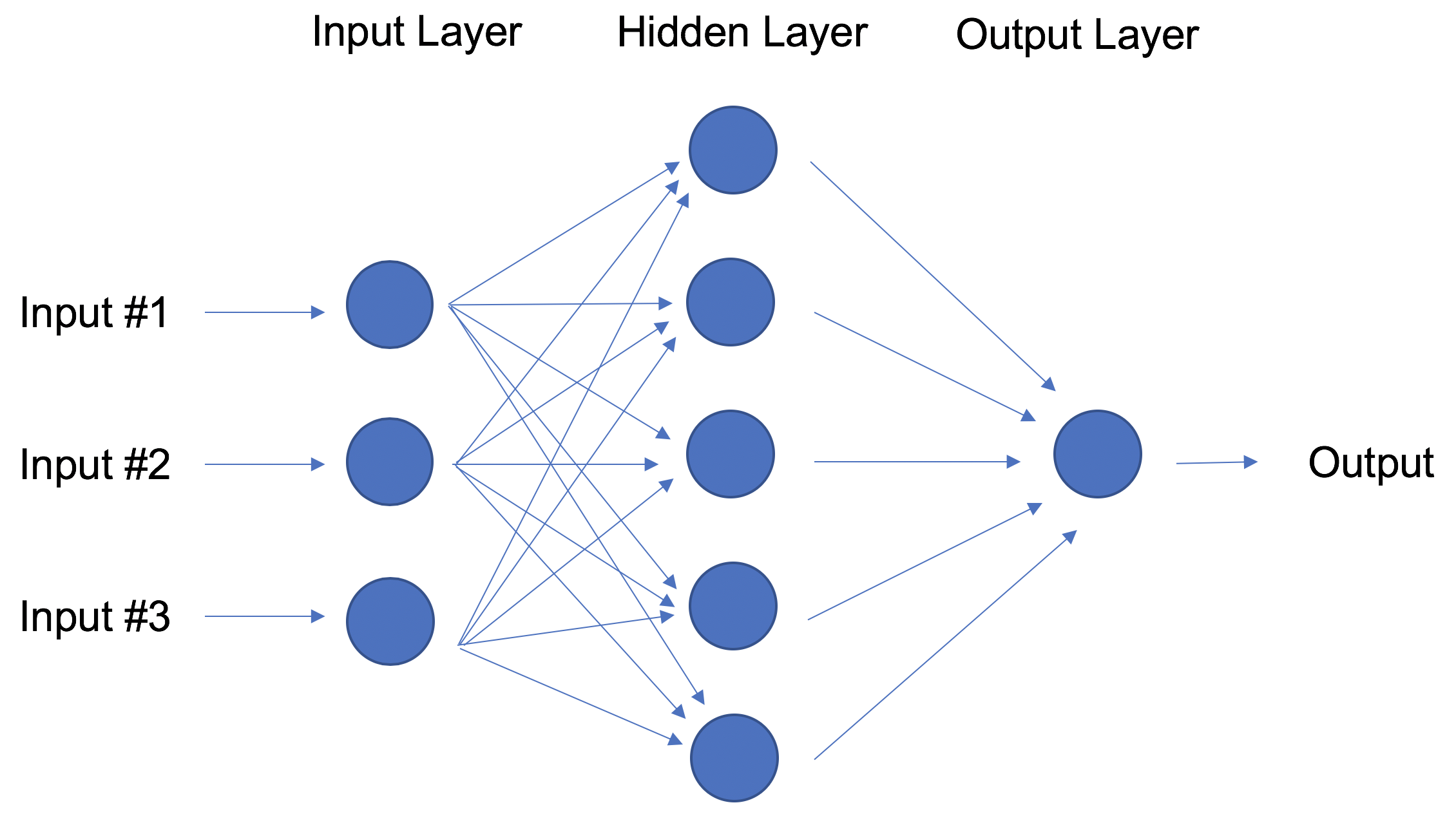 Rede neural com uma camada oculta.
Rede neural com uma camada oculta.
Na verdade, a estrutura das redes neurais é flexível o suficiente para construir nossa conhecida regressão linear e logística. O termo Aprendizado profundo (Deep Learning) vem de uma rede neural com muitas camadas ocultas (consulte a próxima Figura) e encapsula uma ampla variedade de arquiteturas.
É especialmente difícil acompanhar os avanços das arquiteturas de Deep Learning, em parte porque as comunidades de pesquisa e a indústria veem dobrando seus esforços no desenvolvomento da tecnologia, gerando resultados totalmente novas todos os dias.
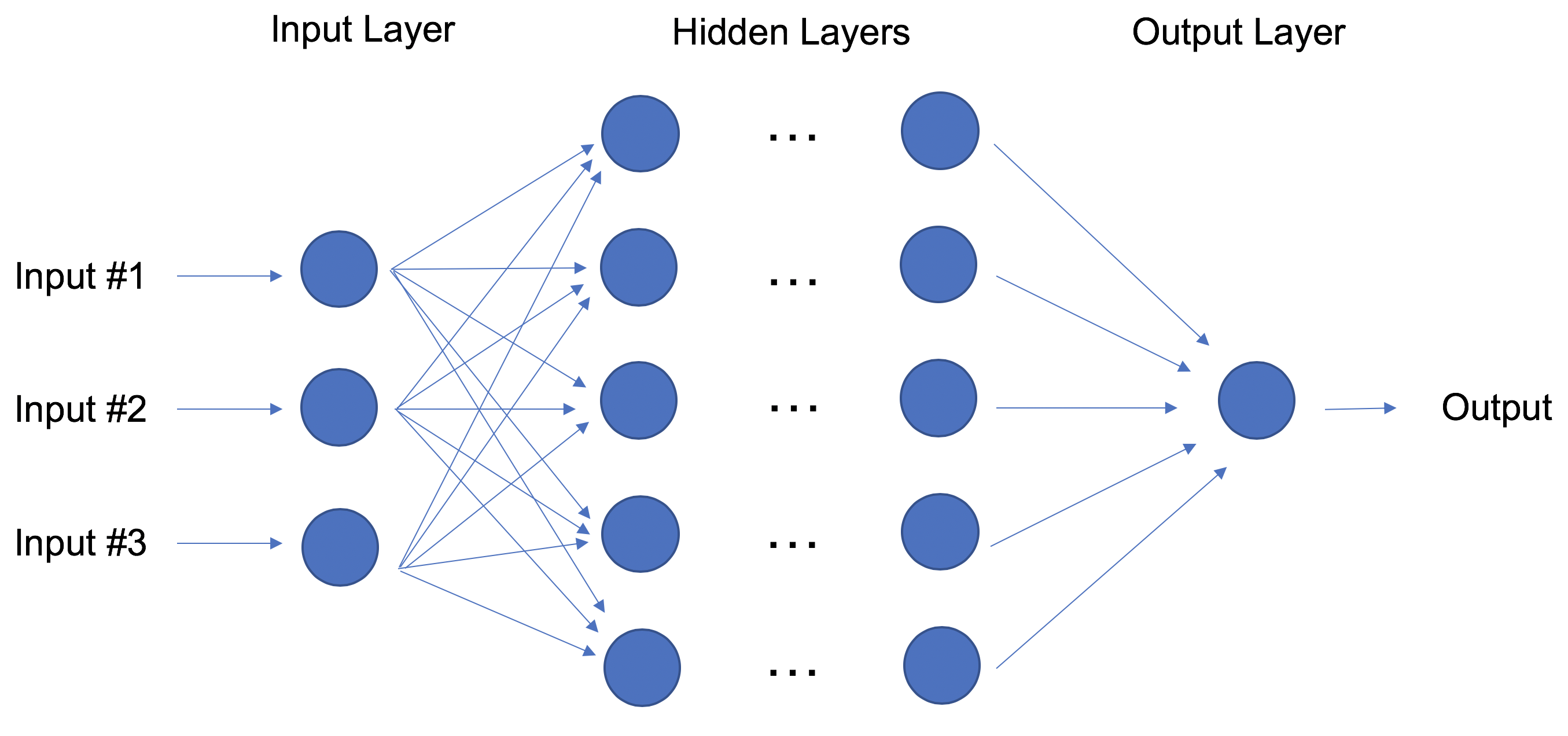 Deep Learning: Rede Neural com muitas camadas ocultas.
Deep Learning: Rede Neural com muitas camadas ocultas.
Para obter o melhor desempenho, as técnicas de deep learning exigem muitos dados - e muito poder de computação, pois o método é autoajustável envolvendo sempre muitos parâmetros em arquiteturas de camadas enormes. Rapidamente tem ficado claro porque os praticantes de deepe learning precisam de computadores muito poderosos aprimorados com GPUs (unidades de processamento gráfico).
Em particular, as técnicas de deep learning têm sido extremamente bem-sucedidas nas áreas de visão computational (classificação de imagens), texto, áudio e vídeo. Os pacotes de software mais comuns para aprendizado profundo são Tensorflow e PyTorch.
Transfer Learning
Suponhamos que você seja um cientista de dados que trabalha no setor de varejo. Você passou meses treinando uma modelo de alta qualidade para classificar as imagens como camisas, camisetas e polos. Sua nova tarefa é construir um modelo semelhante para classificar imagens de vestidos como jeans, cargo, casual e calças sociais. Você pode transferir o conhecimento incorporado ao primeiro modelo e aplicá-lo ao segundo modelo? Sim, você pode, usando o Transfer Learning.
A Transfer Learning refere-se a reutilizar parte de uma rede neural previamente treinada e adaptá-la a uma tarefa nova, mas semelhante. Especificamente, depois de treinar uma rede neural usando dados para uma tarefa, você pode transferir uma fração das camadas treinadas e combiná-las com algumas novas camadas que você pode treinar usando os dados da nova tarefa. Ao adicionar algumas camadas, a nova rede neural pode aprender e se adaptar rapidamente à nova tarefa.
A principal vantagem do Transfer Learning é que você precisa de menos dados para treinar a rede neural, o que é particularmente importante porque o treinamento para algoritmos de deep learning é caro em termos de tempo e dinheiro (recursos computacionais) - e, claro, muitas vezes é muito difícil encontrar dados rotulados suficientes para o treinamento.
Voltemos ao nosso exemplo e suponha que para o modelo de camisa você use uma rede neural com 20 camadas ocultas. Depois de executar alguns experimentos, você percebe que pode transferir 18 das camadas do modelo de camisa e combiná-las com uma nova camada de parâmetros para treinar nas imagens das calças. O modelo da calça teria, portanto, 19 camadas ocultas. As entradas e saídas das duas tarefas são diferentes, mas as camadas reutilizáveis podem resumir informações que são relevantes para ambas, por exemplo, aspectos do tecido.
A Transfer Learning tornou-se cada vez mais popular e agora existem muitos modelos pré-treinados disponíveis para tarefas comuns de deep learning, como classificação de imagem e texto.
Reinforcement Learning
Imagine um rato em um labirinto tentando encontrar pedaços de queijo escondidos. Quanto mais expomos o rato ao labirinto, melhor ele encontra o queijo. No início, o rato pode se mover aleatoriamente, mas depois de algum tempo, a experiência do rato o ajuda a perceber quais ações o aproximam do queijo.
O processo do rato reflete o que fazemos com Reinforcement Learning (RL) para treinar um sistema ou um jogo. De maneira geral, RL é um método de aprendizado de máquina que ajuda um agente a aprender com a experiência. Ao registrar ações e usar uma abordagem de tentativa e erro em um ambiente definido, RL pode maximizar uma recompensa cumulativa. Em nosso exemplo, o rato é o agente e o labirinto é o ambiente. O conjunto de ações possíveis para o rato são: mover para a frente, para trás, para a esquerda ou para a direita. A recompensa é o queijo.
Você pode usar o RL quando tiver pouco ou nenhum dado histórico sobre um problema, porque ele não precisa de informações com antecedência (ao contrário dos métodos tradicionais de aprendizado de máquina).
Em uma estrutura RL, você aprende com os dados à medida que avança. Não surpreendentemente, RL é especialmente bem-sucedido com jogos, especialmente jogos de “informação perfeita” como xadrez e Go. Com os jogos, o feedback do agente e do ambiente chega rapidamente, permitindo que o modelo aprenda rápido. A desvantagem do RL é que pode levar muito tempo para treinar se o problema for complexo.
Assim como o Deep Blue da IBM venceu o melhor jogador de xadrez humano em 1997, AlphaGo, um algoritmo baseado em RL, venceu o melhor jogador de Go em 2016. Os atuais pioneiros do RL são as equipes da DeepMind no Reino Unido. Mais sobre AlphaGo e DeepMind aqui.
Em abril de 2019, a equipe OpenAI Five foi a primeira IA a vencer uma equipe campeã mundial de e-sport Dota 2, um videogame muito complexo que a equipe OpenAI Five escolheu porque não havia algoritmos RL capazes de vencê-lo até então. A mesma equipe de IA que venceu a equipe humana campeã de Dota 2 também desenvolveu uma mão robótica que pode reorientar um bloco. Leia mais sobre a equipe OpenAI Five aqui.
Você pode dizer que o Aprendizado por Reforço é uma forma especialmente poderosa de IA, e temos certeza de ver mais progresso dessas equipes, mas também vale a pena lembrar as limitações do método.
Natural Language Processing
Uma grande porcentagem dos dados e conhecimentos do mundo está em alguma forma de linguagem humana. Você pode imaginar ser capaz de ler e compreender milhares de livros, artigos e blogs em segundos? Obviamente, os computadores ainda não podem entender totalmente o texto humano, mas podemos treiná-los para fazer certas tarefas. Por exemplo, podemos treinar nossos telefones para preencher automaticamente nossas mensagens de texto ou corrigir palavras com erros ortográficos. Podemos até ensinar uma máquina a ter uma conversa simples com um humano.
O Processamento de Linguagem Natural (PNL) não é um método de aprendizado de máquina per se, mas uma técnica amplamente usada para preparar texto para aprendizado de máquina. Pense em toneladas de documentos de texto em uma variedade de formatos (word, blogs online, …). A maioria desses documentos de texto estará cheia de erros de digitação, caracteres ausentes e outras palavras que precisam ser filtradas. No momento, o pacote mais popular para processamento de texto é o NLTK (Natural Language ToolKit), criado por pesquisadores de Stanford.
A maneira mais simples de mapear o texto em uma representação numérica é calcular a frequência de cada palavra em cada documento de texto. Pense em uma matriz de inteiros onde cada linha representa um documento de texto e cada coluna representa uma palavra. Essa representação de matriz das frequências de palavras é comumente chamada de Matriz de frequência de termo (TFM). A partir daí, podemos criar outra representação de bem popular de um documento de texto, dividindo cada entrada na matriz por um peso de quão importante cada palavra é considerando todos os documentos sendo analisados. Chamamos esse método Term Frequency Inverse Document Frequency (TF-IDF) e normalmente funciona muito bem para tarefas de aprendizado de máquina.
Word Embeddings
TFM e TFIDF são representações numéricas de documentos de texto que consideram apenas a frequência e as frequências ponderadas para representar documentos de texto. Por outro lado, os Word Embeddings podem capturar o contexto de uma palavra em um documento. Com a palavra em contexto, os Word Embeddings podem quantificar a semelhança entre as palavras, o que nos permite fazer aritmética com as palavras.
Word2Vec é um método baseado em redes neurais que mapeia palavras em um texto para um vetor numérico. Podemos então usar esses vetores para encontrar sinônimos, executar operações aritméticas com palavras ou representar documentos de texto (tomando a média de todos os vetores de palavras em um documento). Por exemplo, vamos supor que usamos um corpus suficientemente grande de documentos de texto para estimar embeddings de palavras. Suponhamos também que as palavras rei, rainha, homem e mulher fazem parte do corpus. Digamos que o vetor (‘palavra’) é o vetor numérico que representa a palavra ‘palavra’. Para estimar o vetor (‘mulher’), podemos realizar a operação aritmética com vetores:
vector(‘king’) + vector(‘woman’) — vector(‘man’) ~ vector(‘queen’)
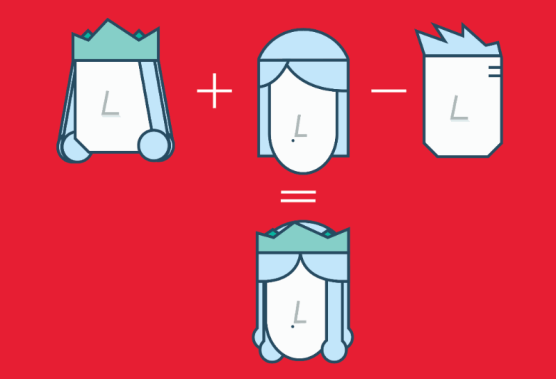
Arithmetic with Word (Vectors) Embeddings.
As representações de palavras permitem encontrar semelhanças entre palavras calculando a semelhança de cosseno entre a representação vetorial de duas palavras. A similaridade do cosseno mede o ângulo entre dois vetores.
Calculamos embeddings de palavras usando métodos de aprendizado de máquina, mas isso geralmente é uma pré-etapa para aplicar um algoritmo de aprendizado de máquina no topo. Por exemplo, suponha que tenhamos acesso aos tweets de vários milhares de usuários do Twitter. Suponha também que sabemos qual desses usuários do Twitter comprou uma casa. Para prever a probabilidade de um novo usuário do Twitter comprar uma casa, podemos combinar o Word2Vec com uma regressão logística. Você mesmo pode treinar embeddings de palavras ou obter um conjunto pré-treinado (aprendizado por transferência) de vetores de palavras. Para baixar vetores de palavras pré-treinados em 157 idiomas diferentes, dê uma olhada em FastText.
Summary
Eu tentei cobrir os dez métodos de aprendizado de máquina mais importantes: do mais básico ao mais moderno. Estudar bem esses métodos e compreender totalmente os fundamentos de cada um pode servir como um ponto de partida sólido para um estudo mais aprofundado de algoritmos e métodos mais avançados.
É claro que ainda há muitas informações importantes a serem abordadas, incluindo coisas como métricas de qualidade, validação cruzada, desequilíbrio de classe nos métodos de classificação e ajuste excessivo de um modelo, para mencionar apenas alguns. Fique ligado.
Todas as visualizações deste blog foram feitas usando o Watson Studio Desktop.
Originally posted here.
{kind=link}